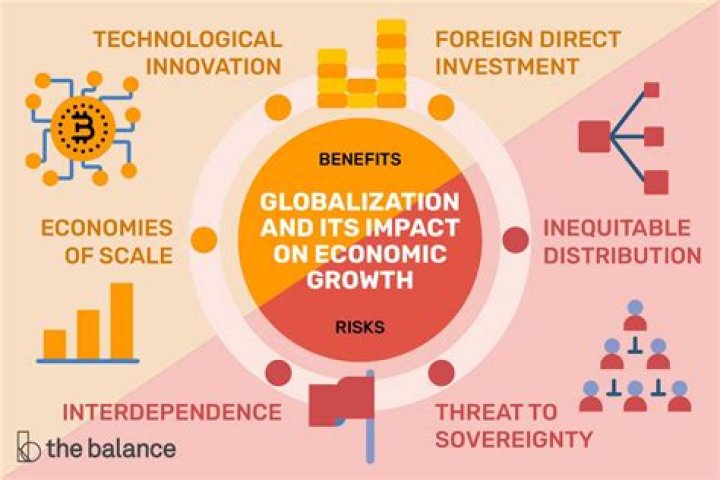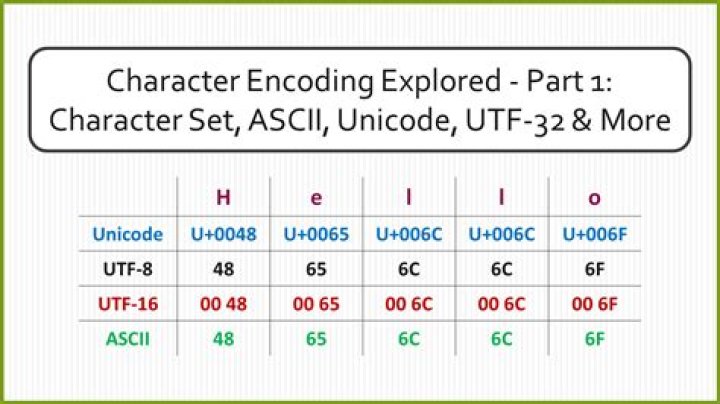
UTF-8 is a variable-width character encoding used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode (or Universal Coded Character Set) Transformation Format – 8-bit.
Does UTF-8 have accents?
UTF-8 is a standard for representing Unicode numbers in computer files. Symbols with a Unicode number from 0 to 127 are represented exactly the same as in ASCII, using one 8-bit byte. This includes all Latin alphabet letters without accents. Viewed in ISO Western, these bytes look like  .
What is the difference between Unicode and UTF-8?
UTF-8 is an encoding used to translate numbers into binary data. Unicode is a character set used to translate characters into numbers.
What is the Unicode code point for UTF-8?
Unicode code point UTF-8 (hex.) name U+0000 00 U+0001 01 U+0002 02 U+0003 03
What is UCSU TF-8?
U TF-8 is an ASCII-preserving encoding method for Unicode (ISO 10646), the Universal Character Set (UCS). The UCS encodes most of the world’s writing systems in a single character set, allowing you to mix languages and scripts within a document without needing any tricks for switching character sets.
What is a tf8 character set?
— Don Knuth U TF-8 is an ASCII-preserving encoding method for Unicode (ISO 10646), the Universal Character Set (UCS). The UCS encodes most of the world’s writing systems in a single character set, allowing you to mix languages and scripts within a document without needing any tricks for switching character sets.
What is the Unicode code point for the Latin capital letters?
Unicode code point character UTF-8 (hex.) name U+00C5 Å c3 85 LATIN CAPITAL LETTER A WITH RING ABOVE U+00C6 Æ c3 86 LATIN CAPITAL LETTER AE U+00C7 Ç c3 87 LATIN CAPITAL LETTER C WITH CEDILLA U+00C8 È c3 88 LATIN CAPITAL LETTER E WITH GRAVE