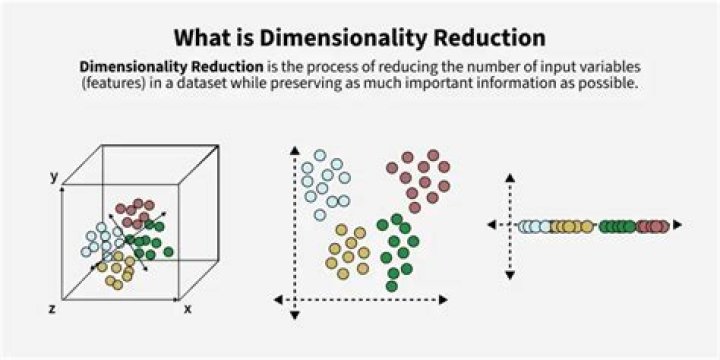
Dimensionality reduction refers to techniques for reducing the number of input variables in training data. When dealing with high dimensional data, it is often useful to reduce the dimensionality by projecting the data to a lower dimensional subspace which captures the “essence” of the data.
What is dimension reduction in data mining?
Dimensionality reduction is the process of reducing the number of random variables or attributes under consideration. High-dimensionality reduction has emerged as one of the significant tasks in data mining applications. For an example you may have a dataset with hundreds of features (columns in your database).
What is dimensionality reduction example?
For example, maybe we can combine Dum Dums and Blow Pops to look at all lollipops together. Dimensionality reduction can help in both of these scenarios. There are two key methods of dimensionality reduction: Feature selection: Here, we select a subset of features from the original feature set.
What are dimension reduction techniques?
Dimensionality reduction technique can be defined as, “It is a way of converting the higher dimensions dataset into lesser dimensions dataset ensuring that it provides similar information.” These techniques are widely used in machine learning for obtaining a better fit predictive model while solving the classification …
Why do we reduce dimensions?
It reduces the time and storage space required. It helps Remove multi-collinearity which improves the interpretation of the parameters of the machine learning model. It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D.
Why is Dimension Reduction important?
What are some techniques that can be applied for dimensionality reduction?
Seven Techniques for Data Dimensionality Reduction
- Missing Values Ratio.
- Low Variance Filter.
- High Correlation Filter.
- Random Forests / Ensemble Trees.
- Principal Component Analysis (PCA).
- Backward Feature Elimination.
- Forward Feature Construction.
Which of the following approaches are used for dimension reduction?
The various methods used for dimensionality reduction include: Principal Component Analysis (PCA) Linear Discriminant Analysis (LDA) Generalized Discriminant Analysis (GDA)
Which is the best technique of data has many dimensions?
The best way to go higher than three dimensions is to use plot facets, color, shapes, sizes, depth and so on. You can also use time as a dimension by making an animated plot for other attributes over time (considering time is a dimension in the data).
What are the approaches of dimension reduction?
Principal Component Analysis (PCA), Factor Analysis (FA), Linear Discriminant Analysis (LDA) and Truncated Singular Value Decomposition (SVD) are examples of linear dimensionality reduction methods.
What do you mean by dimension reduction?
Dimensionality reduction, or dimension reduction, is the transformation of data from a high-dimensional space into a low-dimensional space so that the low-dimensional representation retains some meaningful properties of the original data, ideally close to its intrinsic dimension.
What are the applications of dimensionality reduction?
Application of Dimensionality Reduction 1 Text mining 2 Image retrieval 3 Microarray data analysis 4 Protein classification 5 Face and image recognition 6 Intrusion detection 7 Customer relationship management 8 Handwritten digit recognition
What is the curse of dimensionality in data mining?
The curse of dimensionality is a condition that occurs when we want to classify, organize, and analyze the high dimensional data. When the number of dimensions increases, the distance between two independent points increases, and similarity decreases. This problem results in more errors in our final results after data mining..
What is the difference between dimension reduction and singular value decomposition?
Dimension reduction is an important step in text mining. Dimension reduction improves the performance of clustering techniques by reducing dimensions so that text mining procedures process data with a reduced number of terms. Singular value decomposition is a technique used to reduce the dimension of a vector.
How to reduce dimensionality in machine learning modeling?
Using variance thresholds is an easy and relatively safe way to reduce dimensionality at the start of your modeling process. But this alone will not be sufficient if you want to reduce the dimensions as it’s highly subjective and you need to tune the variance threshold manually.